
Intro
One of the key pillars regarding SRE is being able to make quantitative decisions based on key metrics.
The major challenge is what are key metrics and this is testament to the plethora of monitoring software out in the wild today.
At a foundational level you want to ensure your services are always running, however 100% availability in not practical.
Class SRE implements Devops
{
MeasureEverything()
}Availability/Error Budget
You then figure out what availability is practical for your application and services.
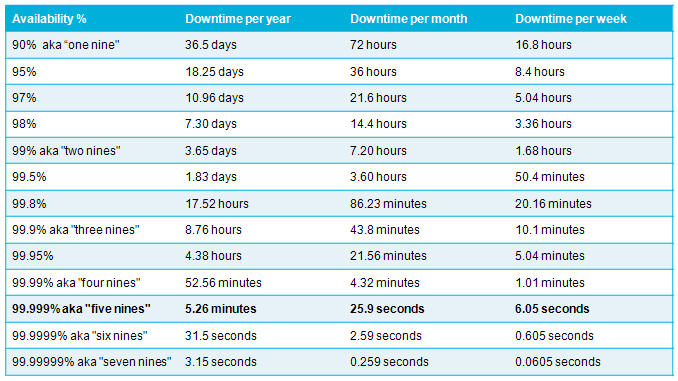
Your error budget will then be the downtime figure e.g. 99% is 7.2 hours of downtime a month that you can afford to have.
SLAs, SLOs and SLIs
This will be the starting point on your journey to implementing quantitative analysis to
- Service Level Agreements
- Service Level Objectives
- Service Level Indicators
This blog post is all about how you can measure Service Level Objectives without breaking the bank. You do not need to spend millions of dollars on bloated monitoring solutions to observe key metrics that really impact your customers.
Just like baking a cake, these are the ingredients we will use to implement an agile, scaleable monitoring platform that is solely dedicated to doing one thing well.
Outcome
This is what we want our cake to deliver:
- Measuring your SLA Compliance Level
- Measuring your Error Budget Burn Rate
- Measuring if you have exhausted your error budget

If you look at the cake above, you can see all your meaningful information in one dashboard.
- Around 11am the error budget burn rate went up. (A kin to your kids spending all their pocket money in one day!)
- Compliance was breached (99% availability) – The purple line (burn rate) went above the maximum budget (yellow line)
These are metrics you will want to ALERT on at any time of the day. These sort of metrics matter. They are violating a Service Level Agreement.
What about my other metrics?
Aaaah, like %Disk Queue Length, Processor Time, Kubernetes Nodes/Pods/Pools etc? Well…
I treat these metrics as second class citizens. Like a layered onion. Your initial metrics should be – Am I violating my SLA? If not, then you can use the other metrics that we have enjoyed over the decades to compliment your observeability into the systems and as a visual aid for diagnostics and troubleshooting.
Alerting
Another important consideration is the evolution of infrastructure. In 1999 you will have wanted to receive an alert if a server ran out of disk space. In 2020, you are running container orchestration clusters and other high availability systems. A container running out of disk space is not so critical as it used to be in 1999.
- Evaluate every single alert you have and ask yourself. Do I really need to wake someone up at 3am for this problem?
- Always alert on Service Level Compliance levels ABOUT to breach
- Always alert on Error Budget Burn Rates going up sharply
- Do not alert someone out of hours because the CPU is 100% for 5 minutes unless Service Level Compliance is being affected to
You will have happier engineers and a more productive team. You will be cooled headed during an incident because you know the different between a cluster node going down versus Service Level Compliance violations. Always solve the Service Level Compliance and then fix the other problems.
Ingredients
Where are the ingredients you promised? You said it will not break the bank, I am intrigued.
- A Kubernetes cluster – Google, Azure Kubernetes Services etc
- ArgoCD – Argo CD is a declarative, GitOps continuous delivery tool for Kubernetes.
- Prometheus
- Service Level Operator
Summary
In this post we have touched on the FOUNDATION of what we want out of monitoring.
We know exactly what we want to measure – Service Level Compliance, Error Budget Burn Rate and Max Budget. All this revolves around deciding on the level of availability we give a service.
We touched on the basic ingredients that we can use to build this solution.
In my next blog post we will discuss how we mix all these ingredients together to provide a platform that is is good at doing one thing well.
Measuring Service Level Compliance & Error Budget Burn Rates
When you give your child $30 to spend a month and they need to save $10 a month. You need to be alerted if they spending too fast (Burn Rate).

