Hey,
I ran into a few issues when I wanted to install Puppet Enterprise 2-17 in AWS as an EC2 instance. The main issues were
Summary
- Need to use hostnamectl and cloud.cfg to change my hostname, as I wanted puppet on a public address, not private address, just for a POC
- I was using a t2.nano and t2.micro, which will not work with Puppet Enterprise 2017 (puppet-enterprise-2017.2.2-el-7-x86_64). The error you get is just Failed to run PE Installer…… So I used a t2.medium to get around the issue.
- The usual /etc/hosts file needs some settings and DNS registration (Route53 for me)
- Disabled SELinux (We usually use a VPN)
- Configure security groups and have 4433 as backup port (Probably not needed)
Preliminary Install Tasks
- Get the latest image from CentOS 7 (x86_64) – with Updates HVM
- Spin up an instance with at least 4GB memory, I had a lot of installation issues with applying the catalog with low memory. T2.Medium should work. Bigger is better!
[puppet.rangerrom.com] Failed to run PE installer on puppet.rangerrom.com. - If you not using a VPN then ensure you setup an elastic IP mapped to the instance for the public DNS name

- Register the hostname and elastic IP in DNS

- Add you hostnames to /etc/hosts (Important!), note I also added puppet as this is the default for installs. This is a crucial step, so make sure you add your hostnames that you want to use. Put the public hostname first. As this is our primary hostname127.0.0.1 puppet.rangerrom.com puppet localhost
- Change the hostname of your EC2 Instance. We need to do the following
#hostnamectl
#sudo hostnamectl set-hostname puppet.rangerrom.com –static
#sudo vi /etc/cloud/cloud.cfg - Add the following to the end of cloud.cfg
preserve_hostname: true - This is the error I got when I first installed puppet (Due to low memory), therefore we will add port 4433 as well to the AWS security in the next step. I think this was due to insufficient memory, so use a T2.Medium instance size, so you have a minimum of 4GB of memory, else java kills itself. However I add it as a backup here in case you run some other service on 443.
#sudo vi /var/log/puppetlabs/installer/2017-08-08T02.09.32+0000.install.log
Failed to apply catalog: Connection refused – connect(2) for “puppet.rangerrom.com” port 4433
- Create a security group with the following ports open and also do the same for the Centos Firewall.
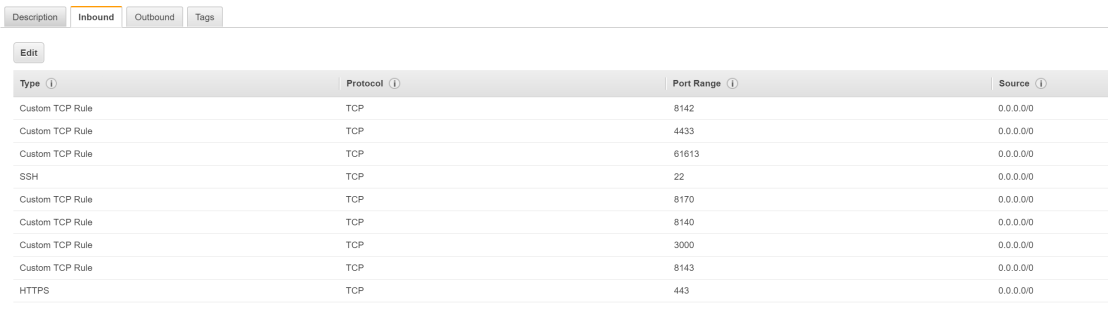
- Run netstat -anp | grep tcp to ensure no port conflicts.
- Disable SELinux or have it configured to work in a Puppet Master environment. Edit
#sudo vi /etc/sysconfig/selinux
set
SELINUX=disabled - Edit the sudo vi /etc/ssh/sshd_config and enable Root Logins
PermitRootLogin yes - Download Puppet Enterprise
#curl -O https://s3.amazonaws.com/pe-builds/released/2017.2.2/puppet-enterprise-2017.2.2-el-7-x86_64.tar.gz
#tar -xvf puppet-enterprise-2017.2.2-el-7-x86_64.tar.gz - Install NC and use it to test if your ports are accessible.
sudo yum install nc
nc -nlvp 3000 (Run in one terminal) - nc puppet 3000 ( Run from another terminal)

This is a great way to ensure firewall rules are not restricting your installation. Secondly we testing that the local server can resolve itself, as it is important that you can resolve puppet and also your custom FQDN before running PE install. - Reboot and run hostnamectl, the new hostname should be preserved.
#sudo hostnamectl set-hostname puppet.rangerrom.com –static
[centos@ip-172-31-13-233 ~]$ hostnamectl
Static hostname: puppet.rangerrom.com
Transient hostname: ip-172-31-13-233.ap-southeast-2.compute.internal
Icon name: computer-vm
Chassis: vm
Machine ID: 8bd05758fdfc1903174c9fcaf82b71ca
Boot ID: 0227f164ff23498cbd6a70fb71568745
Virtualization: xen
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-514.26.2.el7.x86_64
Architecture: x86-64
Installation
- Now that we done all our preinstall checks, kick off the installer.
#sudo ./puppet-enterprise-installer
- Enter 1 for a guided install.
- Wait until it asks you to connect to the server on https://<fqdn>:3000
This is what occurs if you did not configure your hostname correctly and you want a public hostname (EC2 internal is default):

We want our public hostname.

Puppet will basically run a thin web server to complete the installation with the following command:
RACK_ENV=production /opt/puppetlabs/puppet/share/installer/vendor/bundler/bin/thin start –debug -p 3000 -a 0.0.0.0 –ssl –ssl-disable-verify &> /dev/null - Recall, we have the above FQDN in our host file, yours will be your hostname that you setup.
- Visit your Puppetmaster site at https://fqdn:3000
- Ensure in DNS Alias, you add puppet and all other DNS names you want to use. Otherwise the installation will fail.
You should see the correct default hostname, if not, you got issues…. I added some alias names such as puppet and my internal and external ec2 addresses.

- Set an Admin password and click next
- Check and double check the settings to confirm.
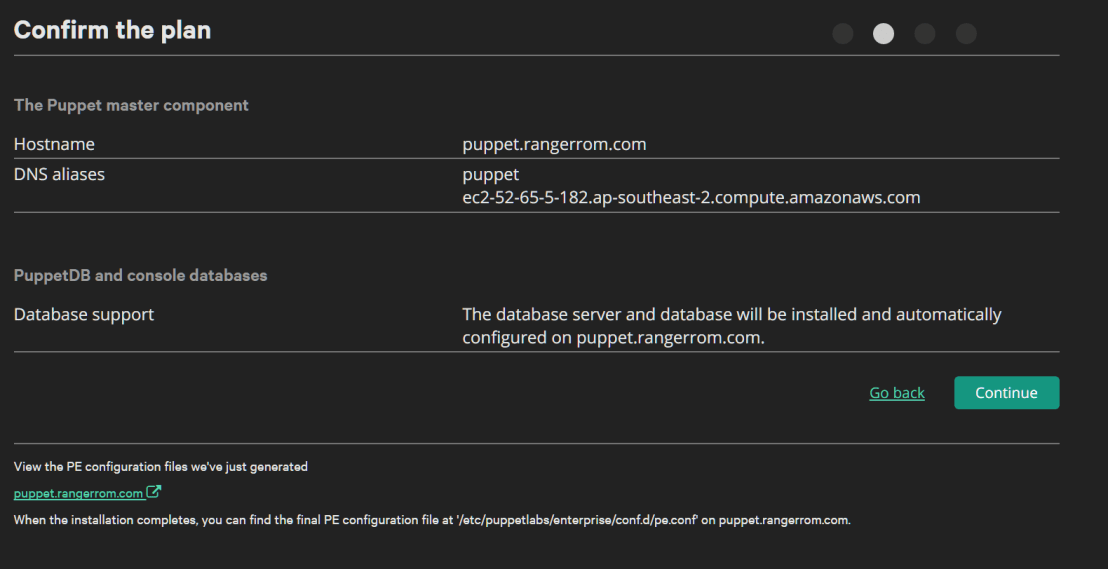
- Check the validation rules, since this is for testing, I am happy with the warnings. It would be awesome if puppetlabs did DNS name resolution validation checks on the HostName. Anyways, here we get a warning about memory, 4GB is what is needed, so if you have install failures it may be due to memory!

- I am feeling lucky, lets try with 3533MB of RAM 🙂




You must be logged in to post a comment.